Hardening a Cloud SaaS for Secure, Scalable Production
The Problem
A modern application has a frustrating duality. It can be "in production" for months - accepting users, returning data, looking healthy on every dashboard - while still being genuinely unsafe to scale or trust with anything important. The default trajectory for most teams is to ship features until something breaks, then react. By the time the team recognizes how much non-feature work the system needs, the cost of catching up has compounded.
This gap - between deployed and production-ready - is invisible to most people outside engineering. From the outside, the product works. The login screen appears. Data flows. Customers can demo. The harder question - what happens when something goes wrong, when a credential leaks, when a region goes down, when a misconfigured deploy ships at 5pm on a Friday - doesn't surface until it matters.
What Production-Ready Actually Means
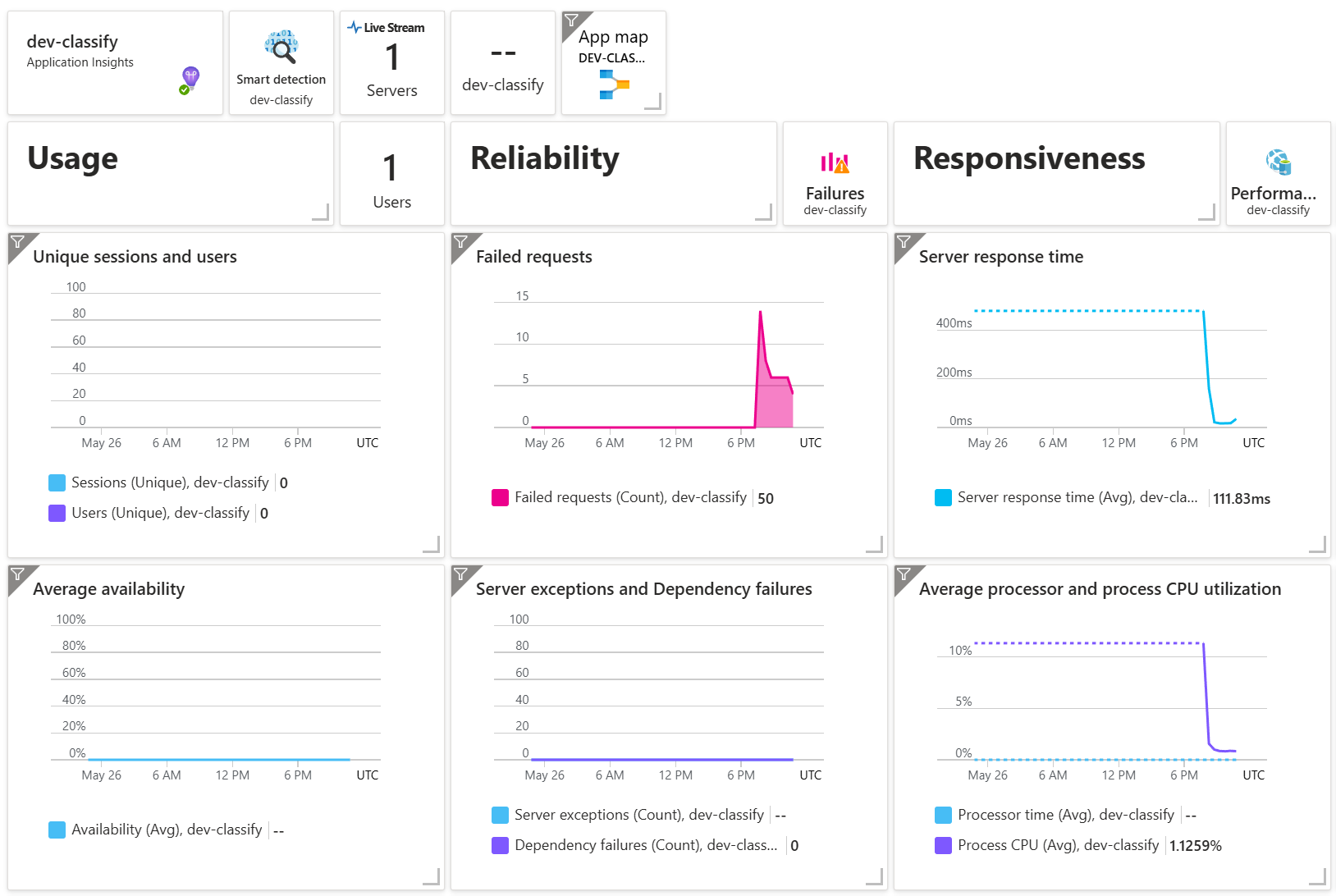
When SoftAtomic approached this problem, most of the work split cleanly into nine dimensions. None of them are visible to a customer. All of them determine whether the platform can handle the moment the customers first put real pressure on it.
Identity and secrets: how the system proves who it is when calling its own dependencies
Tenancy and authorization: how the system guarantees a customer's data stays a customer's data
Networking posture: which doors are open, and to whom
Runtime correctness: what the system does when something is misconfigured, missing, or partially broken
Resilience: what bounds the system enforces under burst, slowdown, or partial failure
CI/CD: whether a deploy is a leap of faith or a verified promotion
Observability: whether an incident is a query or a reconstruction project
Operational runbooks: whether the recovery procedure exists before the incident or during it
Test strategy: whether the tests catch what would actually hurt, not just what's easy to test
A team can ship features for years without closing all of these. They will catch up at the cost of an incident, an audit, or a customer's confidence.
The Patterns Underneath
The specific changes across those nine dimensions number in the dozens, but six patterns carried most of the value. Each one is concrete enough to act on and abstract enough to apply to a different system tomorrow. The sections that follow walk through each - the principle, why it matters, and what it looked like in practice on Azure.
Identity replaces secrets
Every cloud service the platform talks to - database, message queue, storage, AI model - needs to prove who is calling. The default approach is a shared secret: a key, a connection string, a token. Every shared secret is a hostage. It can be leaked, rotated incorrectly, or misconfigured between environments. The modern alternative - managed identity - lets the cloud platform itself vouch for the workload, eliminating the secret entirely.
On Azure, this means DefaultAzureCredential in code, AAD-backed RBAC on every service that supports it, and OIDC federation for GitHub Actions. The few secrets that must remain live in Key Vault, fetched under the same identity. Once nothing in the system holds a rotatable shared secret, an entire category of operational risk goes with it.
Once nothing in the system holds a rotatable shared secret, an entire category of operational risk disappears.
Structural fixes beat per-call-site fixes
The most common class of multi-tenant data leak follows a single shape: "load a record by its ID, then check authorization against the user's request body." Fixing it controller by controller leaves the next controller exposed. Pushing the check down into the data layer - so every query is tenant-scoped by default and the only way to leak is an explicit, code-review-visible opt-out - closes the entire class of bug at once.
A single, EF Core query filter on each tenant-scoped entity makes every database read and write tenant-aware by default, and the only escape hatch - an explicit IgnoreQueryFilters opt-out - is rare and obvious in code review. The same structural instinct shaped the refresh-token rotation logic, the closed-account enforcement middleware, and the per-endpoint rate limits on the auth surface: one place that decides, rather than many places that have to remember.
Silence is a failure mode
Health checks that silently skip on missing config report green while the system is broken. Worker jobs that quietly exit on empty input report success while doing nothing. Anywhere code says "no work to do, return quietly" needs a counter and an alert.
A startup config check throws on missing required values, so a misconfigured deploy fails the platform's startup probe rather than running broken. Silent skips at runtime increment a System.Diagnostics.Metrics counter, surfaced in Application Insights with an alert rule when the count climbs. Logs carry trace, account, and user IDs via Serilog — incident triage becomes a query, not an excavation.
Resilience is mostly about bounds
Resilience comes from bounds — on timeouts, retries, caches, parallelism, connection pools. A system that retries forever and parallelizes to its processor count rather than its connection pool fails under real load no matter how clever its circuit breakers are.
The Azure SDKs make this easy to get wrong by default: settings that suit a request-response API can quietly betray a worker holding a queue message lock. Each SDK client gets an options object with bounds matched to its caller. Caches are sized via MemoryCache; parallel database work is capped to the connection pool; Polly circuit breakers fit on top once the first-order bounds are right.
Deploys earn promotion; they don't claim it
A deploy that says "I'm green in dev, ship me to prod" is a leap of faith. A deploy that promotes the same artifact bit-for-bit, gated on a green integration test for the same commit and deployed by content address rather than mutable tag, is a verified handoff.
The pipeline builds once on dev master-push; a promote-to-prod workflow ships that artifact to production only after verifying the same commit ran green through integration tests within 24 hours. Container images deploy by @sha256:... digest. SBOMs, cosign signatures, and nightly drift checks surround the core. Replace faith with evidence.
Recovery procedures exist before incidents
The moment a database is corrupt or a region is offline is the wrong moment to write the recovery procedure. The right moment is the quiet week before launch — when the team can draft, drill, and refine the procedure with no stakes.
Three runbooks live in the repository alongside the code: a DR procedure covering point-in-time restore and credential rotation, a migration-recovery procedure for failed deploys, and an on-call playbook with first-look queries per alert. The DR procedure is drilled in a sandbox before the first paying customer.
Why This Matters
The moment a database is corrupt, a credential is compromised, or a region is offline is the wrong moment to write the recovery procedure. The right moment is the quiet week before launch - when the team can draft, drill, and refine the procedure with no stakes.
Three runbooks live in the repository alongside the code: a disaster-recovery procedure covering point-in-time restore against Azure SQL and credential rotation; a migration-recovery procedure for schema repair after a failed deploy; and an on-call playbook with a first-look query per alert. Before the first paying customer, the disaster-recovery procedure gets drilled once in a sandbox to verify it actually works. Deferred operational trade-offs - SKU choices, geo-restore, compliance asks - land in a decision register with the trigger that should bring each one back into scope.
When This Work Pays Off
This is the work that closes the gap between a product that runs and a product a business can stake its name on:
Approaching a first paying customer. The conversation goes differently when the platform has been hardened.
Moving from pilot to production. A pilot tolerates fragility. A production deployment doesn't.
Adding regulated industries - healthcare, finance, government, insurance. The audit will surface this work either way; the only question is whether it's already done.
Preparing for due diligence. An acquirer, investor, or enterprise procurement team reading the platform sees this work as a maturity signal.
Onboarding a new operator or engineering lead. The inheriting team needs runbooks, infrastructure code, and structural decisions - not tribal knowledge.
Recovering after an incident. The post-mortem almost always traces back to one of the nine dimensions; the question is which one was unaddressed first.
Technical Architecture
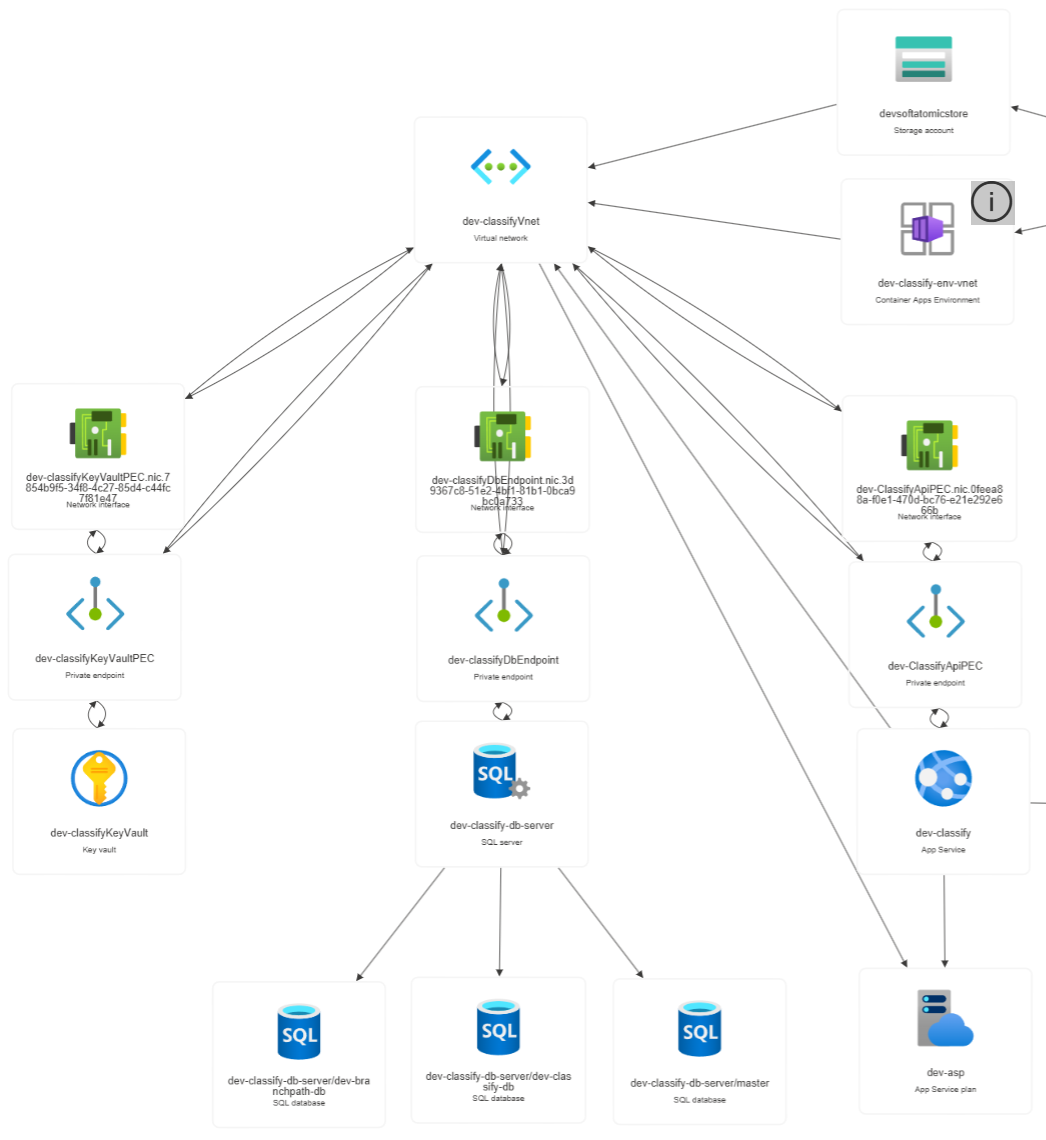
Identity & access: Microsoft Entra ID, Azure managed identity, Azure Key Vault, GitHub OIDC federation
Infrastructure as code: Bicep, declarative role assignments and resource locks
CI/CD & supply chain: GitHub Actions, Azure Container Registry, content-addressed image deploys, cosign image signing, SBOM generation, scheduled drift detection
Observability & alerting: Azure Application Insights, Azure Log Analytics, Azure Monitor, custom metrics, scheduled-query alert rules
Compute, data, and AI services: Azure App Service, Azure Container Apps, Azure SQL with point-in-time restore, Azure Service Bus, Azure OpenAI, Azure AI Search
Closing Thought
If you're approaching a launch, preparing for due diligence, or have inherited a platform that needs to grow up, SoftAtomic does this. We harden new systems before they ship and bring existing ones up to a posture that can survive customer pressure. Contact Us.
