Building an Intelligent, Configurable Data Classification Platform
Modern AI has made automated classification more capable than ever - and less interpretable than ever. When a neural network or large language model infers a result, the reasoning is often distributed across billions of parameters that no one can audit. For companies in demanding industries trying to build with AI products, the lack of transparency is a major barrier to understanding how decisions are made.
At the same time, the data being classified is rarely clean. The world is a messy place - sensors and inputs are noisy, people make mistakes, descriptions can differ wildly and still mean the same thing. Rigid rule-based systems fail under this ambiguity. A powerful but opaque model trades one problem for another.
The Evolution
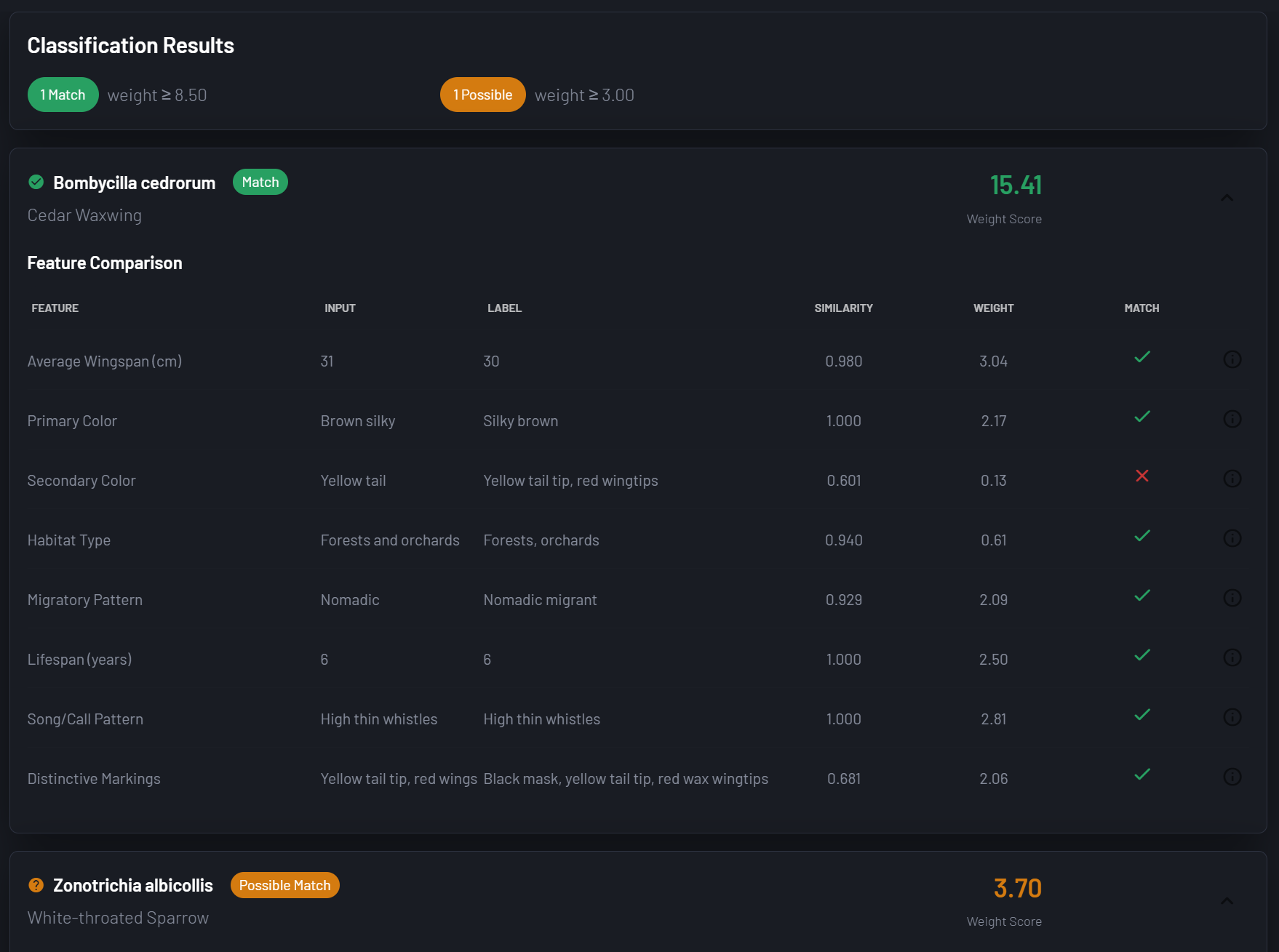
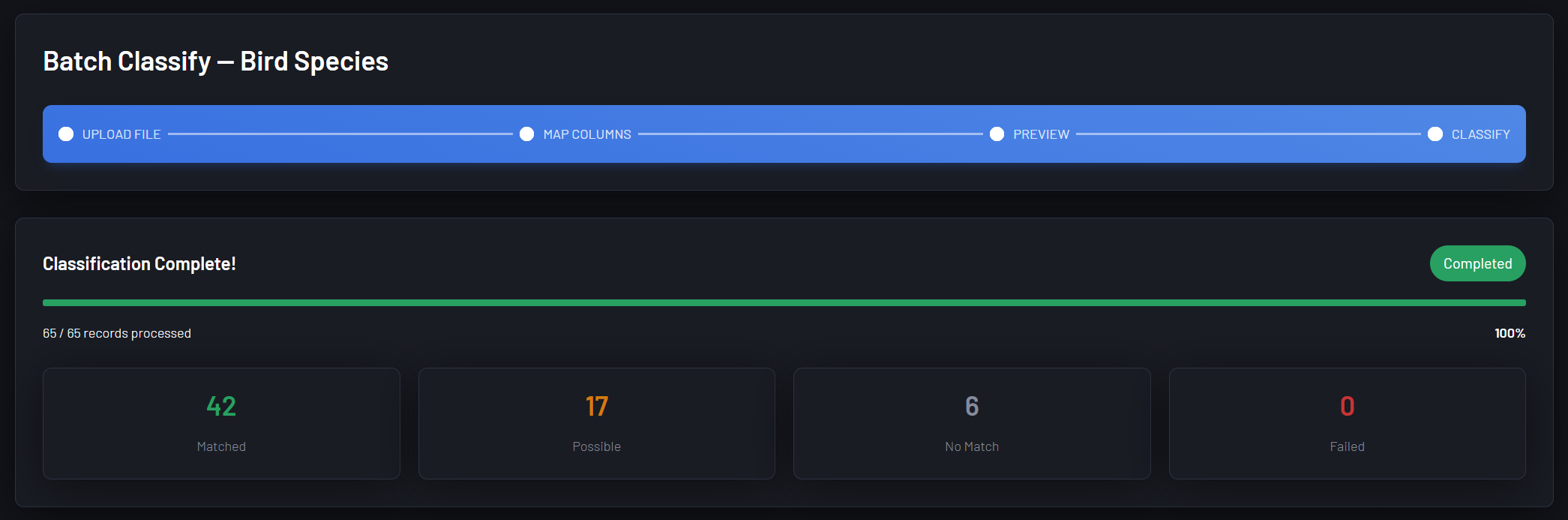
SoftAtomic Classify is a fully configurable classification platform that lets teams define their own taxonomies, choose how each feature should be evaluated, and fine tune comparison methods - without writing code or training models.
And the architecture generalizes further than that; at its core, the platform is a configurable evidence accumulation engine: define what signals matter, define how to measure them, set a threshold for confidence, and get a ranked, explainable determination.
For teams building on top of AI, the challenge isn't getting a model to produce an answer - it’s knowing what do with it, and how much to trust it. Model outputs are rarely definitive - they're signals. SoftAtomic Classify gives those outputs somewhere to land: a structured reasoning layer that can weigh AI signals alongside human-defined rules, domain knowledge, and other inputs to produce a determination that a human can read, audit, and defend.
Pluggable Design
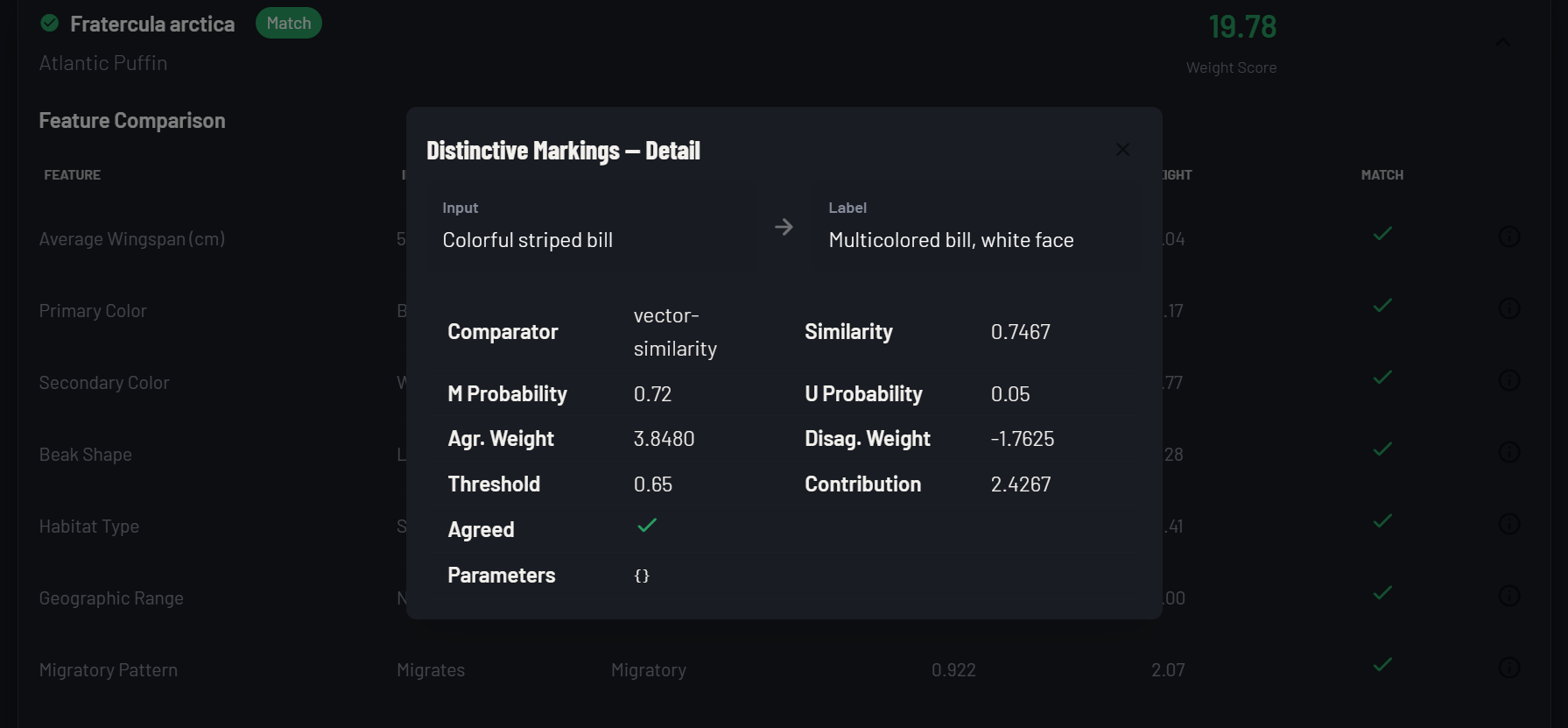
Comparators are pluggable by design. That means a comparator isn't limited to simple equality or similarity functions - it can run inference against an AI model, call an external API, or aggregate the outputs of multiple models into a single weighted signal. The result is a platform that can absorb AI outputs along with other signals as evidence, reason transparently about what they collectively imply, and produce a confidence-weighted determination with a full audit trail. Not a black box on top of a black box — a structured reasoning layer that makes AI outputs legible and actionable.
The inputs can be AI. The comparators can be AI. The output can feed AI. Or it can feed another classification taxonomy entirely — and the chain continues. What the platform provides at every step is the one thing most AI pipelines lack: a legible account of why.
Probabilistic Determinism
The classification platform can produce value beyond sorting. The taxonomy of labels can be defined around whatever concepts are operationally meaningful. That could mean:
Is there an anomaly in this transaction stream? → Is that anomaly consistent with known fraud patterns? → Which known pattern does it most closely resemble?
Is there a foreign object in the sensor field? → Is it behaving in a manner consistent with a threat profile? → Which threat profile does it match most closely?
Does this patient presentation match a known condition? → How confidently? → Which treatment protocol does that condition map to?
Is this contract clause materially similar to a flagged clause? → How similar? → Which regulatory risk category does it fall under?
Each of these is a chain of classification problems, each feeding the next. The output of one determination becomes an input to the next — a label in a downstream taxonomy, a feature in a subsequent scoring pass, or a signal fed back into an AI model for further inference.
Applications
Autonomous systems and situational awareness: When a system makes a consequential decision — is that object a threat, an obstacle, or noise — someone has to be able to explain why it decided what it did.
Medical record reconciliation: match patients across providers, systems, and jurisdictions where identifiers don't align
Scientific and clinical research: classify trial results, literature citations, or experimental records against established taxonomies
Fraud and anomaly detection: surface records that closely — but not exactly — match known patterns
Supply chain provenance: reconcile vendor and product records across partner systems with inconsistent data standards
Regulatory compliance: classify documents and transactions against audit frameworks with full explainability for review
Multi-source record deduplication: merge product catalogs, contact databases, or reference datasets from disparate origins
Technical Architecture
Frontend: React, Material-UI, Azure Static Web App
Backend: .NET, C#, Azure App Service, Azure SQL
AI Services: Azure OpenAI (semantic embeddings), Azure AI Search (vector candidate pre-filtering)
Algorithm: Fellegi-Sunter-inspired probabilistic matching with pluggable comparator registry
Closing Thought
The hardest part of working with imperfect data isn't finding the answer - it's knowing how confident to be in it, and being able to say why. Classify was built for that problem.